
Winter Break is over and it’s time to fire up the SCOTUS doctrinal mapping machine! I’ll start 2015 by looking back at my last post. No, this is not early-onset nostalgia for 2014. I first need to correct an error in that post. My interest, however, extends beyond setting the record straight. Understanding what went wrong last time helps explain the very nature of this project and why I call this blog “In Progress.”
Let’s start with the post in question. If you don’t feel like re-reading, here’s the basic gist. I posited that Confrontation Clause doctrine post-Crawford could be visualized as a tussle between three camps: the bashers, builders, and swing vote. I argued that Justice Thomas was the swing vote “since he has voted with the majority in every single case in this line.” This map represents the argument (click for full size):
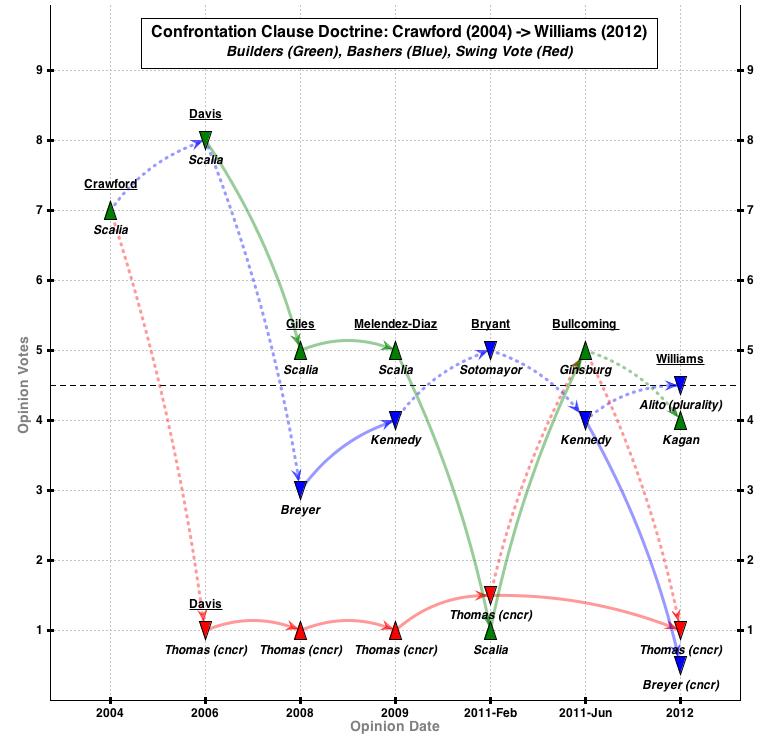
After putting this out into the blogosphere, I was lucky enough to hear back from two of the leading Confrontation Clause scholars in the country — Richard Friedman and George Fisher. Both professors kindly pointed out that Davis v. Washington opinion actually decided two cases (Davis plus Hammon v. Indiana) and that Thomas was the lone dissenter in Hammon. So it is decidedly not true that Thomas has voted with the majority in every post-Crawford case.
How did this error occur? The short answer is that I improperly assumed that Davis and Hammon could be plotted as a single data point. No doubt this was a rookie mistake. Had I closely read the Davis opinions, I would have realized that Thomas joined the Court in denying Adrian Davis relief but dissented from granting Hershel Hammon relief. Yet I did not create the map by reading. Instead, I automatically generated a citation network using CourtListener and then coded that network using Supreme Court Database (Spaeth) data. And both CourtListener and Spaeth incorrectly identify Davis as a single datapoint.
In fairness, CourtListener’s “error” is really not an error at all. The fact is that Davis/Hammon share the exact same citation so any citation-based network has to treat the cases as one. Put another way, no unique cite exists for the Hammon case decided by the Supreme Court on June 19, 2006. The practice of deciding two cases under a single caption will similarly confound every search engine — including Lexis, Westlaw, Fastcase, Ravel and so on.
On the other hand, Spaeth might have done better. That database is populated by human readers who theoretically code every case for many variables including decision direction (liberal vs conservative) and majority vote count. Under such a schema, the two cases really should be treated distinctly since the decision direction differed (the criminal defendant lost in Davis but won in Hammon) as did the majority vote-count (9-0 in Davis verus 8-1 in Hammon). In any event, it seems that the Court’s single-citation-for-two-cases practice should be added to the list of “watch outs” for scholars using Spaeth.
The Davis/Hammon hiccup stands as a good example of the kinds of challenges involved in applying network theory to understanding Court doctrine. Automatically generating citation networks is a powerful tool, but the Court’s complex hermeneutic practices require constant refining of the maps created by the tool. Now I call this blog “In Progress” because I am interested in publicly exploring this continual process of refinement. I thus happily invite others — experts or interested amateurs — to help me figure out when and why the tool gets it wrong or misses something. Progress is a community effort.
With respect to the specific Davis/Hammon problem, I have an imperfect fix. This is what it looks like:
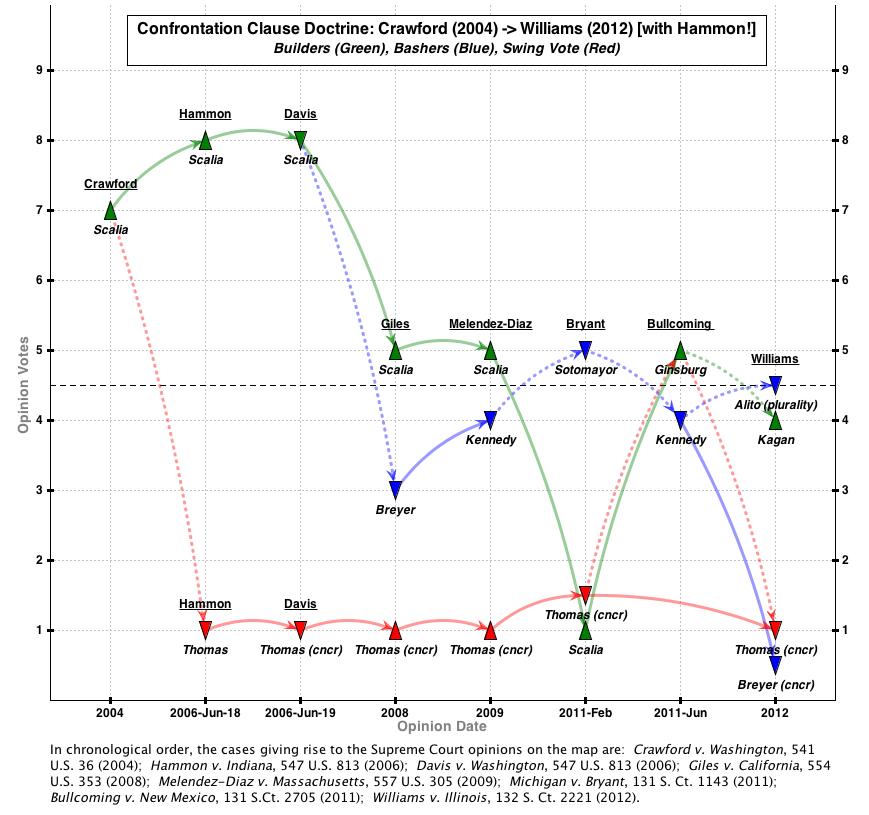
As a reminder, upward-facing triangles on the map represent opinions advocating in favor of the confrontation right/criminal defendant while downward facing triangles represent the opposite. Note how Hammon now appears to the left of Davis on the map and how Thomas’ opinion is marked as a 1-vote dissent rather than concurrence. Note also how I kludged Hammon‘s date to separate it from Davis — failing to do this would result in the datapoints appearing on top of each other.
So the fix ain’t pretty, but at least it’s progress. Or so I hope. Comments more than welcome!
** Postscript ** Based on a comment from the SCOTUS Mapper’s very own Darren Kumasawa (see below), I must note that Spaeth actually DOES properly record Hammon and Justice Thomas’ dissent in it. It just does not do this in the dataset we use (which is the citation-centered set rather than the issue-centered set). The existence of two datasets with not completely consistent data means that you still need to “watch out while using Spaeth”. However, I was quite wrong to imply that the good folks over at the Supreme Court Database failed to get their coding right on Hammon. My apologies! Once more, this is why I call this blog “In Progress”!!
Remind me again why we thought legal data was a good area to work in? I took a look at this with an eye towards improving the data on CourtListener, but I can’t think of anything that’d work. I was hoping there would be a way that we could split the text of the decision or a way to otherwise fix it, but it’s pretty clear that it’s a single decision that should really have two captions.
I’m not sure I love your solution either because it implies that Hammon cites Davis. But since they do have different vote counts, and that’s what you’re plotting, I suppose you don’t have much of an option, short of an asterisk or something along those lines.
Messy data, messy results, I suppose. Interesting problem.
I don’t think this is a problem with Spaeth, but instead a problem with the specific dataset used by SCOTUS Mapper. The application integrates with the “Justice Centered Data: Cases Organized by Supreme Court Citation” dataset (http://scdb.wustl.edu/_brickFiles/2014_01/SCDB_2014_01_justiceCentered_Citation.csv.zip) which unfortunately collapses multiple issues into a single citation group (each judges vote on a single citation is only listed once).
Instead, perhaps the SCOTUS Mapper should use the “Justice Centered Data: Cases Organized by Issue/Legal Provision Including Split Votes” dataset (http://scdb.wustl.edu/_brickFiles/2014_01/SCDB_2014_01_justiceCentered_Vote.csv.zip). In this file, the votes for Davis v. Washington and Hammon v. Indiana are listed separately (even though they share the same 547 U.S. 813 citation) and Thomas’ dissent on Hammon is clearly noted.
This is a problem when you don’t have a lawyer write your code. 🙂
Thanks Mike. It is indeed a noodle-scratcher of a problem. As I said in the post, I really don’t think CourtListener has an “error.” It’s more like an impossible task. The only institution that can really solve it is the Court and I’m not holding my breath…
Aha! The plot thickens. Looks like I may need to add ANOTHER post to correct this post. I had opened the “Cases Organized by Supreme Court Citation” file to make sure that Hammon wasn’t in there. I should have also looked at “Justice Centered Vote.” Hmmm, must scratch my head some more.
Meanwhile, for anyone reading these comments who doesn’t know Darren — he is the not-lawyer who did write the Mapper code!!
Hi Mike, the “Justice Centered Data: Cases Organized by Issue/Legal Provision Including Split Votes” dataset (http://scdb.wustl.edu/_brickFiles/2014_01/SCDB_2014_01_justiceCentered_Vote.csv.zip) is pretty interesting. In this file, Davis v. Washington and Hammon v. Indiana have separate “docketId” (2005-070-01 and 2005-070-02) and “caseIssuesId” values (2005-070-01-01 and 2005-070-02-01), but share the same “caseId” (2005-070), date and citation values (“usCite” = 547 U.S. 813). Pretty tricky…
It’s a sad fact, but nonetheless a fact, that Colin is still constantly having to explain things like this to me. 🙂