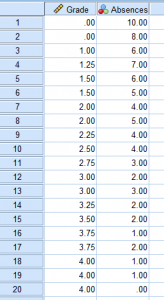
A correlation requires at least 2 continuous variables. We need to first define our variables in Variable View. In this case, we’re looking at how number of absences relates to grade point average.

Next, we type in our data points in Data View.

A correlation requires at least 2 continuous variables. We need to first define our variables in Variable View. In this case, we’re looking at how number of absences relates to grade point average.
Next, we type in our data points in Data View.
A regression can be seen as a kind of extension of a correlation. When doing a regression, you find a lot of the same outputs, like Pearson’s r and r-squared. The difference is that the point of a regression is to also construct a model (usually linear) that will help us predict values using a line of best fit. In the case of this example, we will be looking at average hours of sleep students get and comparing it to their GPA. A regression will also give us a model (y=mx+b) that would allow us to predict the GPA of a hypothetical student if we knew the average amount of sleep they get a night.
First, we need to create our variables in Variable View.

Then, we need to input our data into Data View. You can’t see it in this photo, but I have 25 participants total. Continue reading
Many statistical tests run on the assumption that the data with which you are working is normally distributed, so it’s important to check. There are several different ways to go about this,. This post will explain a few different methods for testing normalcy as well as provide some instructions about how to run these tests in Excel.
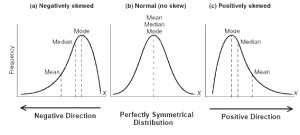
An important rule to note about distribution is that in a normal distribution, the mean, median, and mode are approximately equal. What it looks like visually is that the mean, median, and mode are all sitting at the top of the hump of the bell curve. When a distribution is skewed, these values become different. The mode will always sit around the hump of a distribution (because this is where most of the values have accumulated). The mean is the measure of central tendency most affected by extreme variables and outliers, so it will follow the longest tail. The median, in this case, will always fall somewhere between the median and the mode. Put another way, if the distribution is positively skewed, the mean will be the greatest value, the median will be the second greatest value, and the mode will be the smallest value. If the distribution is negatively skewed, the mean will be the smallest value, the median will be the second smallest value, and the mode will be the greatest value. So when you’re looking at a data set, you may be able to get an idea of the skew of the distribution by comparing the mean and the median.