Reading graphs of two-way ANOVAs is often a little frustrating at first for students who are new to reading them. The goal of this post is to hopefully make the process more straight-forward.
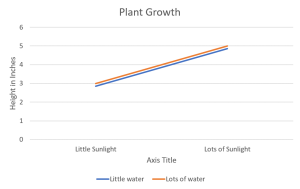
If you’re not sure already what a main effect or interaction is, I would suggest heading over to another post about two-way ANOVAs first. The purpose of one of these graphs is to help the reader visualize the results of the test when reading the results can sometimes be overwhelming, especially if the researchers are working with several different levels in each independent variable. The first trick to remember is that when looking for a significant main effect in the variable on the X-axis, we want the mean distance between the two points above one condition to be different from the mean distance between the two points of another condition. A clear example of this is below. The middle point between the orange line and blue line above “Little Sunlight” is around 2.8, while the middle point between the orange line and blue line above “Lots of Sunlight” is about 4.8. Given the context, we would say that there is a main effect for sunlight in which plant growth increases as levels of sunlight increase.