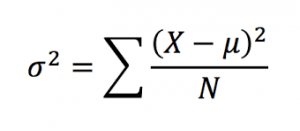Introduction to the t-statistic
Z-tests vs. t-tests
Z-tests compare the means between a population and a sample and require information that is usually unavailable about populations, namely the variance/standard deviation. Single sample t-tests compare the population mean to a sample mean, but only require one variance/standard deviation, and that’s from the sample. This is where estimated standard error comes in. It’s used as an estimate of the real standard error, σM, when the value of σ is unknown. It is computed using the sample variance or sample standard deviation and provides an estimate of the standard distance between a sample mean, M, and the population mean, μ, (or rather, the mean of sample means). It’s an “error” because it’s the distance between what the sample mean is and what it would ideally be since we would rather have the population standard deviation. The formula for estimated standard error is s/√n.
The formula for the t-test itself is: 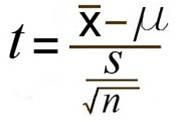 with the bottom portion referring to the estimated standard error. You may see this written as sM instead. Continue reading
with the bottom portion referring to the estimated standard error. You may see this written as sM instead. Continue reading