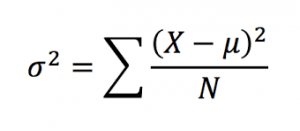Independent One-way ANOVA
An ANOVA (ANalysis Of VAriance) is a test that is run either to compare multiple independent variables with two or more levels each, or one independent variable with more than 2 levels. You can technically also run an ANOVA in the same cases you would run a t-test and come up with the same results, but this isn’t common practice, as t-tests are easier to compute by hand.
For the purposes of this post, a One-way ANOVA is a test which compares the means of multiple samples (more than 2) which are connected by the same independent variable. An example of this might be comparing the growth of plans who receive no water (Group 1) a little water (Group 2), a moderate amount of water (Group 3), and a lot of water (Group 4).
A factor is another name for an independent variable. As mentioned earlier, ANOVAs can sometimes have more than one factor, but for now we’re only working with one, just like we have before. A level is a group within that independent variable. Using the example from before, the groups in which the plants are put in are the levels (no water, little water, some water, a lot of water) and the independent variable itself is just water amount. Continue reading
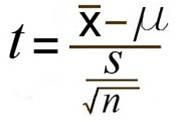 with the bottom portion referring to the estimated standard error. You may see this written as sM instead.
with the bottom portion referring to the estimated standard error. You may see this written as sM instead.