
Introduction to Two-Factor ANOVAs
So far we’ve talked about tests which are used if there is one independent variable, either with two levels or more. This is not the limit of how much we can include in a single analysis. In a two-factor ANOVA, there is more than one independent variable and each of those variables can have two or more levels. Take this example into consideration:
A farmer wants to know the best combination of products to use to maximize her crop yield. She decides to test out three different fertilizer brands (A, B, and C) and two different kinds of seeds (Y and Z). Each product is paired once with another for a total of 6 conditions: AY, BY, CY, AZ, BZ, CZ.
A two-factor ANOVA considers more than one factor and considers the joint impact of factors. This means that instead of running a new study every time you want to see how an independent variable affects a specific dependent variable, you can run an experiment with two different independent variables and seeing how they each impact the dependent variable and you get to see if the two independent variables do anything together to affect the dependent variable. These are called main effects and interactions. Keeping the example going, if we find that no matter what the seed type is that fertilizers A, B, and C resulted in different crop yields from one another, we would say there is a main effect for fertilizer type. If no matter what the fertilizer type is there is a difference between the crop yields of seeds Y and Z, we would say that there is a main effect for seed type. If there are times that the two factors influence each other (for example, let’s say that fertilizer worked much better specifically when paired with Y seeds), we would say there’s an interaction. The defining characteristic of an interaction is when the effect of one factor depends on the different levels of a second factor or the impact of another factor, either amplifying or reducing the effect based on the level. Continue reading
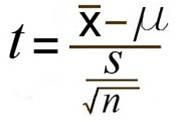 with the bottom portion referring to the estimated standard error. You may see this written as sM instead.
with the bottom portion referring to the estimated standard error. You may see this written as sM instead.