Repeated Measures One-way ANOVA
Just like when we talked about independent samples t-tests and repeated measures t-tests, ANOVAs can have the same distinction. Independent one-way ANOVAs use samples which are in no way related to each other; each sample is completely random, uses different individuals, and those individuals are not paired in any meaningful way. In a repeated measures one-way ANOVA, individuals can be in multiple treatment conditions, be paired with other individuals based on important characteristics, or simply matched based on a relationship to one another (twins, siblings, couples, etc.). What’s important to remember that in a repeated measures one-way ANOVA, we are still given the opportunity to work with multiple levels, not just two like with a t-test.
Advantages:
- Individual differences among participants do not influence outcomes or influence them very little because everyone is either paired up on important participant characteristics or they are the same person in multiple conditions.
- A smaller number of subjects needed to test all the treatments.
- Ability to assess an effect over time.
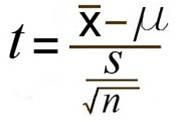 with the bottom portion referring to the estimated standard error. You may see this written as sM instead.
with the bottom portion referring to the estimated standard error. You may see this written as sM instead.